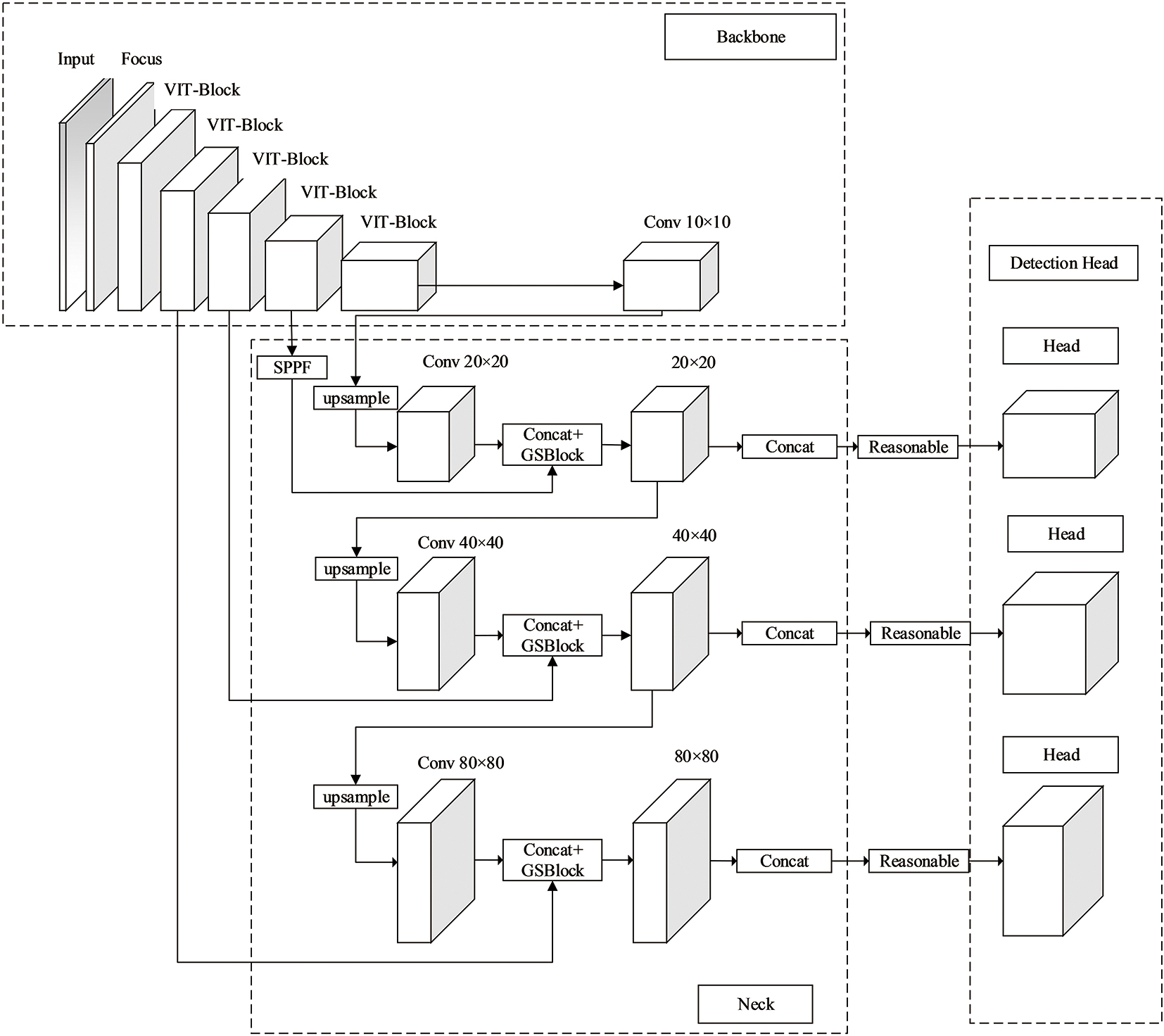
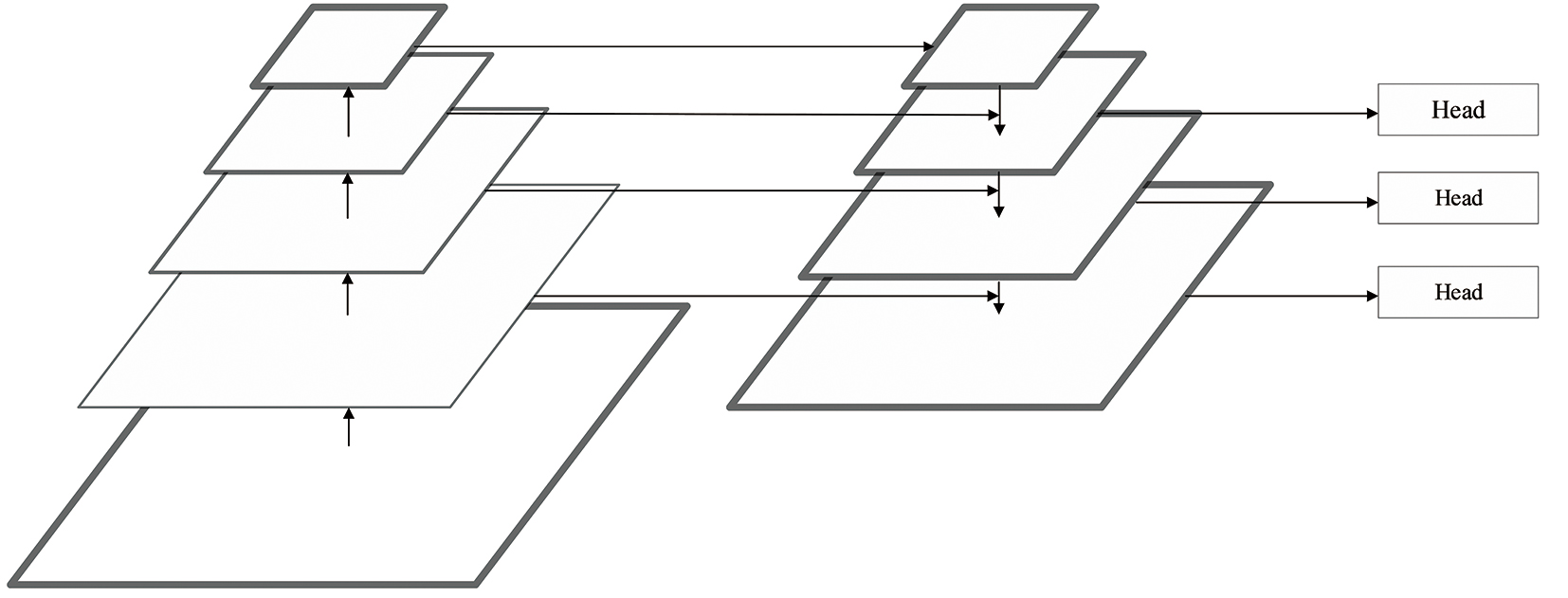
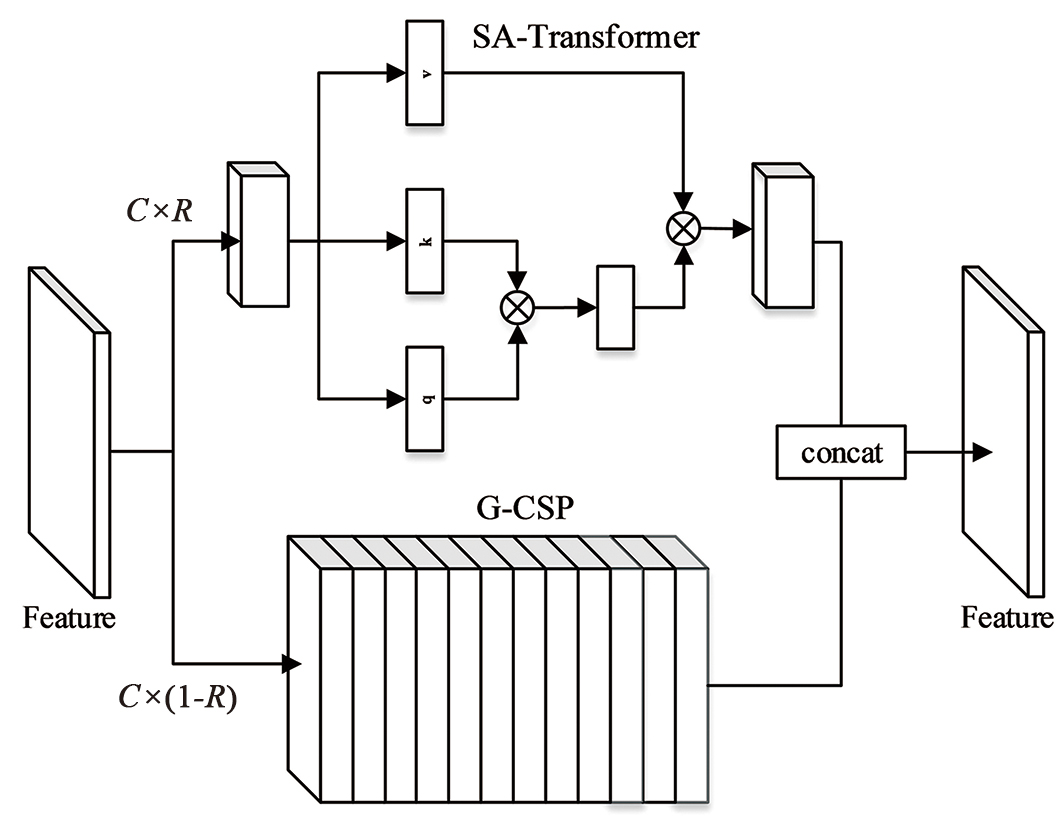
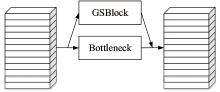
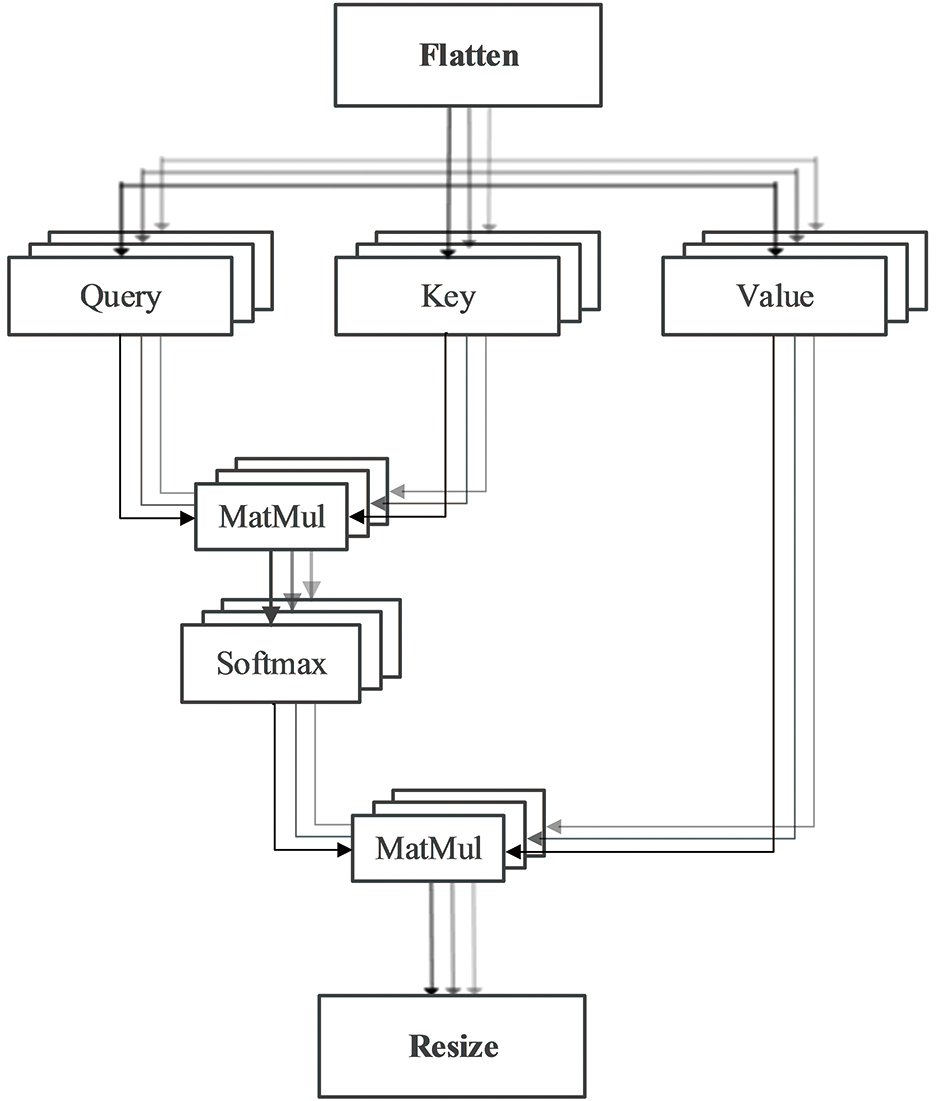
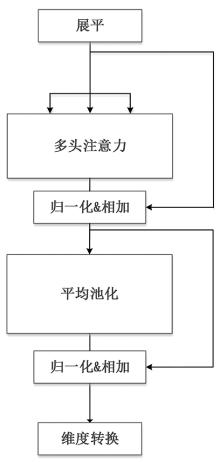
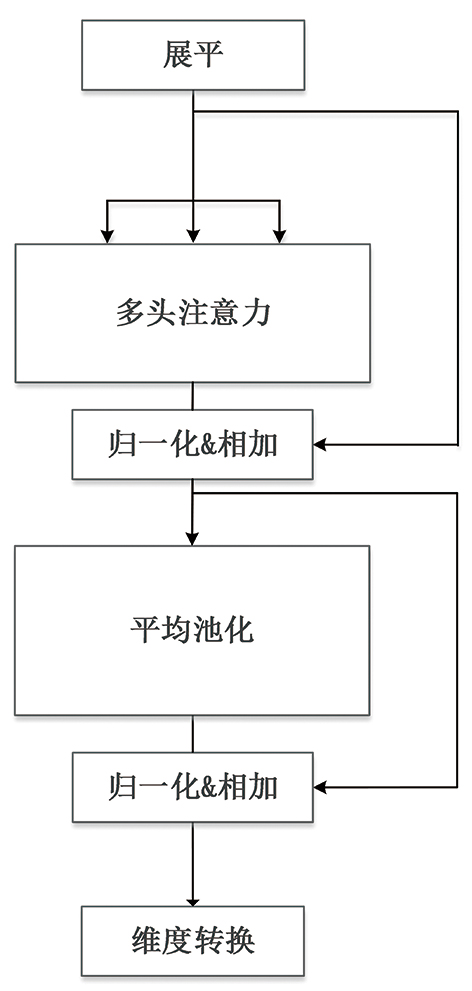
| [1] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 770-778. DOI: 10.1109/CVPR.2016.90.
|
| [2] |
张新钰, 高洪波, 赵建辉, 等. 基于深度学习的自动驾驶技术综述[J]. 清华大学学报(自然科学版), 2018, 58(4): 438-444. DOI: 10.16511/j.cnki.qhdxxb.2018.21.010.
|
| [3] |
邵将, 颜克彤, 姚君, 等. 头戴式AR界面目标符号的视觉搜索实验研究[J]. 东南大学学报(自然科学版), 2020, 50(1): 20-25. DOI: 10.3969/j.issn.1001-0505.2020.01.003.
|
| [4] |
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014: 580-587. DOI: 10.1109/CVPR.2014.81.
|
| [5] |
GIRSHICK R. Fast R-CNN[C]// 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015: 1440-1448. DOI: 10.1109/ICCV.2015.169.
|
| [6] |
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. DOI: 10.1109/TPAMI.2016.2577031.
pmid: 27295650
|
| [7] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 779-788. DOI: 10.1109/CVPR.2016.91.
|
| [8] |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]// European Conference on Computer Vision. Cham: Springer, 2016: 21-37.10.1007/978-3-319-46448-0_2.
|
| [9] |
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(2): 318-327. DOI: 10.1109/TPAMI.2018.2858826.
|
| [10] |
DOSOVTSKIY A, BEYER L, KOLESNKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale[EB/OL]. [2024-03-26]. https://doi.org/10.48550/arXiv.2010.11929.
|
| [11] |
李丽芬, 黄如. 引入Transformer的道路小目标检测[J]. 计算机工程与设计, 2024, 45(1): 95-101. DOI: 10.16208/j.issn1000-7024.2024.01.013.
|
| [12] |
庞玉东, 李志星, 刘伟杰, 等. 基于改进实时检测Transformer的塔机上俯视场景小目标检测模型[J/OL]. 计算机应用, 2024:1-10[2024-03-26]. https://link.cnki.net/urlid/51.1307.TP.20240402.2133.013.
|
| [13] |
罗漫, 李军. 基于CNN技术和DETR的智能汽车自动驾驶道路智能识别的研究[J]. 长江信息通信, 2023(11): 32-34.
|
| [14] |
LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 936-944. DOI: 10.1109/CVPR.2017.106.
|
| [15] |
LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 8759-8768. DOI: 10.1109/CVPR.2018.00913.
|
| [16] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach,California, USA: ACM, 2017: 6000-6010. DOI: 10.5555/3295222.3295349.
|
| [17] |
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012: 3354-3361. DOI: 10.1109/CVPR.2012.6248074.
|
| [18] |
SEITA D. BDD100k: a large-scale diverse driving video database[EB/OL]. [2024-03-26]. http://bdd-data.berkeley.edu.
|
| [19] |
ZHOU X Y, WANG D Q, KRAHENBUHL P. Objects as points[EB/OL]. [2024-03-26]. https://doi.org/10.48550/arXiv.1904.07850.
|
| [20] |
WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[EB/OL]. [2024-03-26]. http://arxiv.org/abs/2207.02696.
|
 ), 高尚兵1,2,*(
), 高尚兵1,2,*(